






How to Deploy Kafka Connect on Kubernetes using Helm Charts
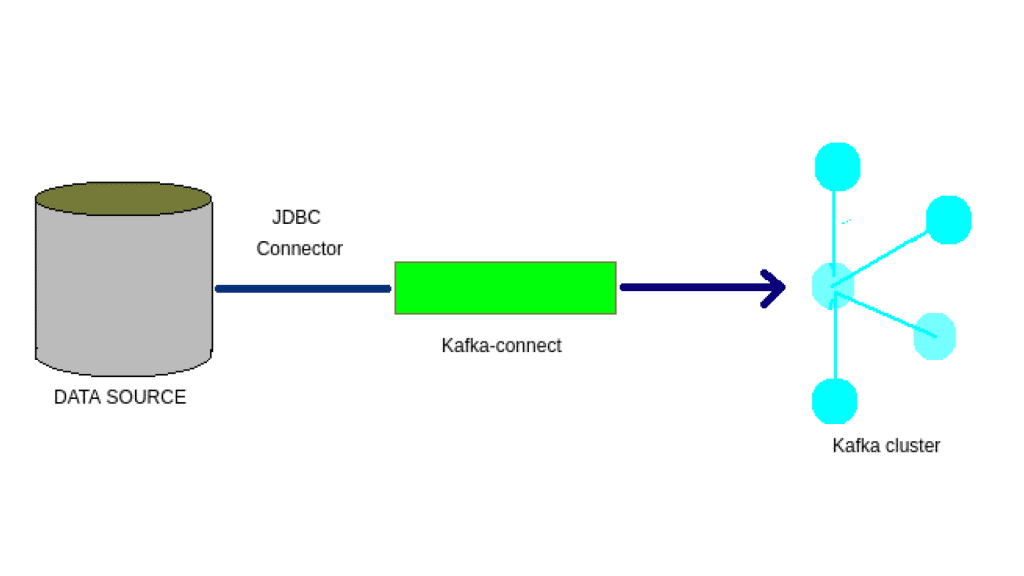
Learn how to deploy Kafka Connect on Kubernetes with step-by-step instructions using Helm charts. This guide covers setting up Kafka brokers, Zookeeper, and custom Kafka Connect containers with JDBC connectors for seamless integration between Kafka and external systems like MySQL databases






